


昨今、ディープラーニングが流行していますが、
今日時点の手法においては、欠点もあります。
実際にAIの適用を考える段階で、
“AIのモデルを生成した結果、何故、そのような分類結果となったのか?”を
説明することができないという点です。
このように、分類結果の根拠を説明できない手法群を“説明不可能なAI”と呼びます。
一方で、“説明可能なAI”の代表例として
決定木と呼ばれる手法が存在します。
本記事では同手法の概要を紹介します。
決定木は所謂、教師あり学習であり、
出力として予測精度および、
どのデータが重要であったかを示す重要度を
算出することが可能です。
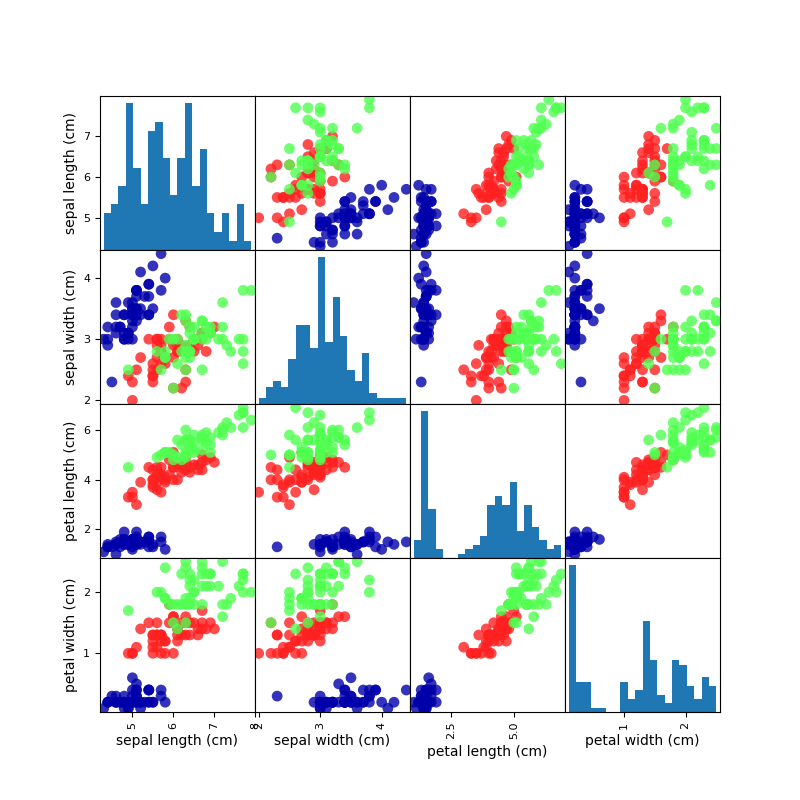
試しに、下の散布図行列に示すirisデータを決定木で分類してみます。
散布図の結果から、pedal widthやlengthのデータに着目すれば
適切に分割できるように見受けられます。
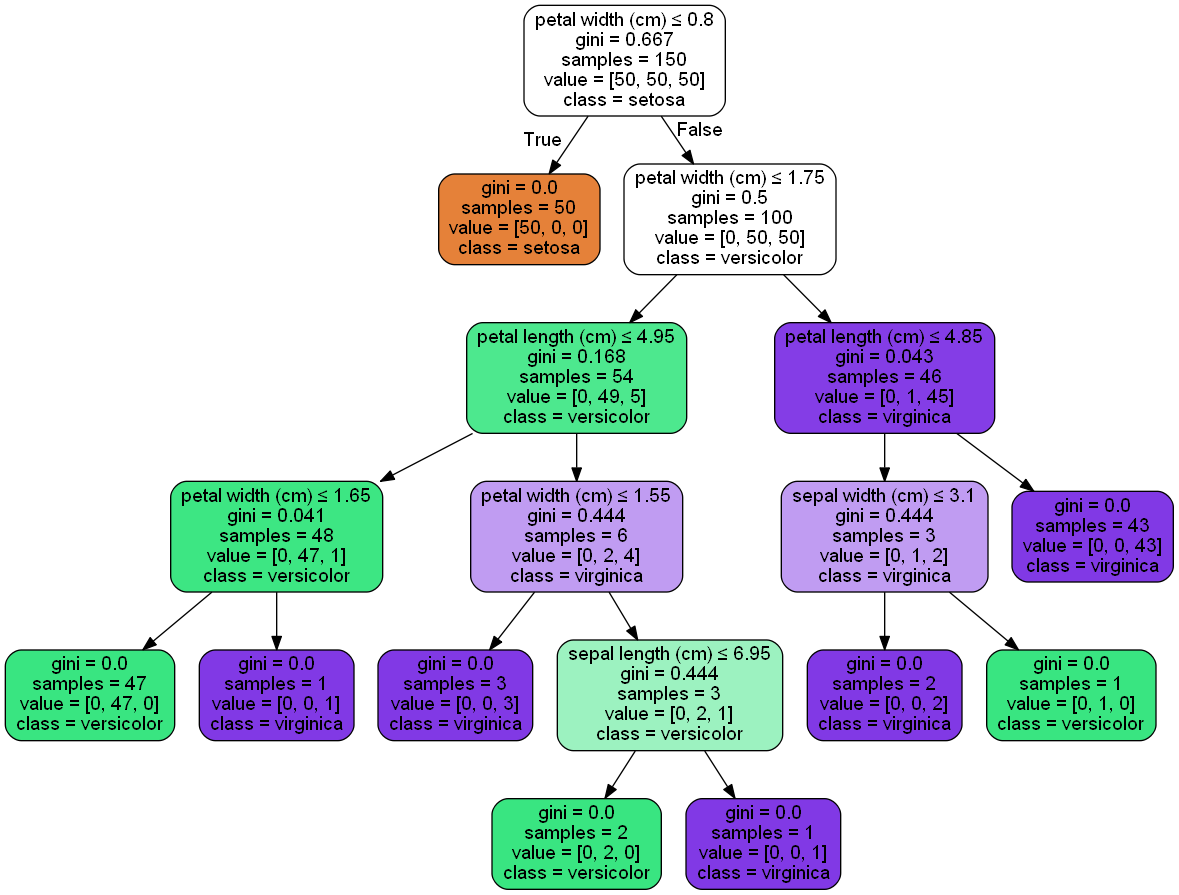
次に、決定木でモデルを生成し、その構造を可視化しました。
・決定木は木構造を用いて空間を分割します。
・決定木は各分類ラベルを情報利得(図中の場合、”gini”の値)に基づいて分類をします。この値は、分類結果の各グループにおいて、ラベルが混在していない度合を定量的に示しています。この値が小さければ、綺麗に分類できていると言えます。
可視化結果を見ると、pedal widthやlengthを条件に、
枝を作っている箇所が木の根の近くに存在しており、
同データらが重要そうだと言えそうです。
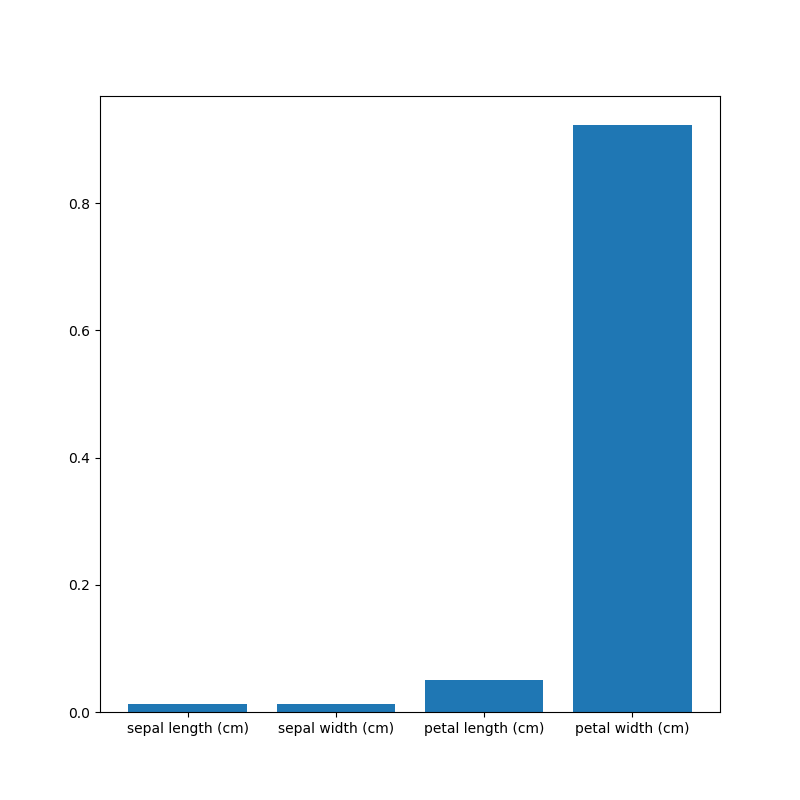
さらに、重要度を可視化してみました。
値が高ければ重要であり、今回の分類事例においては、
全4種のデータのうちpedal widthが最も重要だと定量的に言えます。
このことは、上述の散布図から見受けた判断を裏付けることになり、
分類の根拠と言えます。
決定木はディープラーニングにはできない、上述のような根拠を提示することが可能です。ディープラーニングと比べると、精度は劣りますが、スモールスタートで妥当性を確認したい場合などは有効な手法だと言えます。