(標本平均)
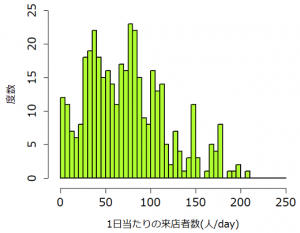
例えば、あるりんご園からりんご 5 個 をサンプリングした結果、そのりんごの重さ $(\mathrm{g})$ がそれぞれ、
\begin{align*}
288&&292&&305&&298&&290
\end{align*}
であったとします。標本の平均値は、
\begin{align*}
\overline{X}=\frac{288+293+305+298+291}{5}=295
\end{align*}
となりますが、これは母集団の平均ではありません。
今回たまたま得られた標本の平均値から、母集団の平均値が
$~~~~~~~~$1. $~~300\,\pm5$ の範囲にある 確率 はいくらか?
$~~~~~~~~$2.「$99.9$% の確率でこの 範囲 に入る」と言えるのは、$295\,\pm$ いくらか?
のような疑問に対する答えを考えていきましょう。
(間違い例)
不偏分散 $s^2$ は、
\begin{align*}
s^2=\frac{1}{n-1}\sum_{i=1}^n\left(X_i-\overline{X}\right)^2
\end{align*}
によって求められる、母集団の 分散 $\sigma^2$ の 推定値 になります。上の例でいえば、
\begin{align*}
s^2=\frac{(288-295)^2+\cdots+(291-295)^2}{5-1}=44.5
\end{align*}
になります。
$s=\sqrt{44.5}\approx 6.67$ なので、正規分布と見なして、$295 \pm 3s=295\pm20$ の範囲に $99.7$% の確率で入るだろう、ということはやってはいけません。
(確率変数の変換)
確率変数 $X$ の 期待値 $E(X)$ および 分散 $V(X)$ が、
\begin{align*}
E(X)=\mu\,,&&V(X)=\sigma^2
\end{align*}
であるとき、定数 $a,b$ によって $X$ からつくられた確率変数 $Y=aX+b$ は、
\begin{align*}
E(Y)=a\mu+b\,,&&V(Y)=a^2\sigma^2
\end{align*}
という性質を持ちます。いま、確率変数 $X$ が、正規分布 $\mathrm{N}\left(\mu,\sigma^2\right)$ に従うとき、
\begin{align*}
Z=\frac{X-\mu}{\sigma}
\end{align*}
は、標準正規分布 $\mathrm{N}\left(0,1^2\right)$ に従います。
同様に、
\begin{align*}
\overline{X}=\frac{X_1+X_2+\cdots+X_n}{n}
\end{align*}
は、$X_1,X_2,\cdots,X_n$ が独立であることから、
\begin{align*}
E(\overline{X})&=\frac{E(X_1)}{n}+\frac{E(X_2)}{n}+\cdots+\frac{E(X_n)}{n}=n\cdot\frac{\mu}{n}=\mu~,\\[6pt]
V(\overline{X})&=\frac{V(X_1)}{n^2}+\frac{V(X_2)}{n^2}+\cdots+\frac{V(X_n)}{n^2}=n\cdot\frac{\sigma^2}{n^2}=\frac{\sigma^2}{n}
\end{align*}
が成り立ち、$\overline{X}$ は正規分布 $\mathrm{N}\left(\mu,\sigma^2/n\right)$ に従いますので、
\begin{align*}
Z=\frac{\overline{X}-\mu}{\sqrt{\dfrac{\sigma^2}{n}}}
\end{align*}
は、標準正規分布 $\mathrm{N}\left(0,1^2\right)$ に従います。
(カイ二乗分布)
上述の 分散 $\sigma^2$ は、ある 決まった値 です。これに対して、私たちが用いようとしている 不偏分散 $s^2$ は、
\begin{align*}
E\left(s^2\right)=\sigma^2
\end{align*}
ではあるものの、推定値 であり、分布 をもっています。
この $\dfrac{n\cdot s^2}{\sigma^2}$ の分布を、自由度 $n-1$(図中の $k$)の $\chi^2$ 分布 (カイ二乗分布)と呼びます。
($t$ 分布)
では、
\begin{align*}
Z=\frac{\overline{X}-\mu}{\sqrt{\dfrac{\sigma^2}{n}}}
\end{align*}
の $\sigma^2$ の代わりに、分布をもった $s^2$ を用いた
\begin{align*}
t=\frac{\overline{X}-\mu}{\sqrt{\dfrac{s^2}{n}}}
\end{align*}
はどのような分布となるのでしょうか。
この分布を Student(発表者のペンネーム)の $t$ 分布 と呼びます。$t$ 分布の自由度 $\nu$ は、$\nu=n-1$ となります。
(母平均の推定)
例えば、初めの例 $(n=5)$
\begin{align*}
288&&292&&305&&298&&290
\end{align*}
でいえば、
\begin{align*}
t=\frac{295-\mu}{\dfrac{6.67}{\sqrt{5}}}
\end{align*}
であり、$\mu=295, 305$ に相当する $t$ はそれぞれ $t=0,-0.67$ であるから、自由度 $4$ の $t$ 分布を調べて、
\begin{align*}
&P\left(\mu \lt 295 \right) = P \left(t \gt 0\right)=0.50~,\\
&P\left(\mu \gt 305 \right)=P\left(t \lt -0.67\right)=0.270
\end{align*}
なので、母集団の 平均値 $\mu$ が $300\pm5$ にある確率は
\begin{align*}
1-\left((P\left(\mu \lt 295 \right)+P\left(\mu \gt 305 \right)\right) =0.33,
\end{align*}
つまり、 $33.0$% と求めることができます。