


機械学習の手法は多く存在しており、
データの対象や目的によって、選定する必要があります。
製造業において不良を発見したい場合、「正常」「異常」の正解ラベルを付与し、
分類問題として考えても良いですが、
一般に、製造業における製品の不良率は1%未満であることが多く、
データセットの内訳として正常データと異常データが同数ではないケースが大半です。
そのような場合は「異常検知(外れ値検出)」の手法を用いるべきです。
Isolation Forestは異常検知のアルゴリズムの一種です。
異常検知手法①でお伝えしたLOFは密度分布に基づいており、
「疎であれば異常、密であれば正常」という考えで異常度を算出します。
Isolation Forestもその考えに基づきますが、
密度を算出するわけでなく、”空間分割の多さ”によって異常であるかを判断します。
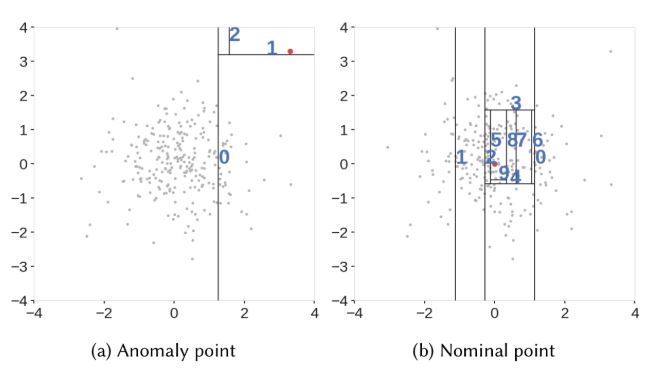
下図[1]は、ある2次元のデータに対してIsolation Forestを適用した例です。
Isolation Forestはサンプルデータ群の空間において、
1つの空間内に属するデータが規定の個数になるまで、分割を繰り返します。
結果的に同図(a)のような疎なデータの空間分割数は2に、
同図(b)のような密なデータの空間分割数は9となり、
差異が生じることがわかります。
LOFは密度の計算を行うために、近傍点を収集する計算処理コストが大きいですが、
Isolation Forestは空間分割法を使うことで、高速に処理することが可能です。
[1]…Hariri, Sahand; Carrasco Kind, Matias; Brunner, Robert J. (2019). “Extended Isolation Forest”. IEEE Transactions on Knowledge and Data Engineering より抜粋